2023. 7. 17. 17:53ㆍpython
https://www.kaggle.com/datasets/kumarajarshi/life-expectancy-who?resource=download
Life Expectancy (WHO)
Statistical Analysis on factors influencing Life Expectancy
www.kaggle.com
오늘은 기대수명에 대한 조사를 한다.

여기에 컬럼이 나와있고, 판다스에서 columns를 조회해도 된다.

Key questions가 있는데 이것을 번역해보니까 이렇게 나온다.
# 선택하여 열 이름 변경하기
# 전체는 df.coulumns = ['col1','col2'...]
df.rename(columns={'Life expectancy ':'Life expectancy'}, inplace=True)컬럼의 특정이름을 다시 지정할 때는 이렇게 하면 된다고 한다. 전체 컬럼을 다시할 때도 주석처리 되어있으니 확인하기. 지금 Life expectancy 뒤에 공백이 있어서 없앤 작업을 한 것이다. 딕셔너리 값으로 매칭 시켜줘야 하고 inplace True 해줘야 한다.
import random
# hexadecimal 형식으로 랜덤 색 선택
def rand_color():
return '#' + "".join([random.choice('0123456789ABCDEF') for _ in range(6)])
# 숫자 컬럼만 선택
numerical_columns = df.select_dtypes(include=[np.number]).columns.tolist()
# 서브블롯의 행을 계산
num_cols = len(numerical_columns)
num_rows = num_cols // 4
num_rows += num_cols % 4
position = range(1, num_cols+1)
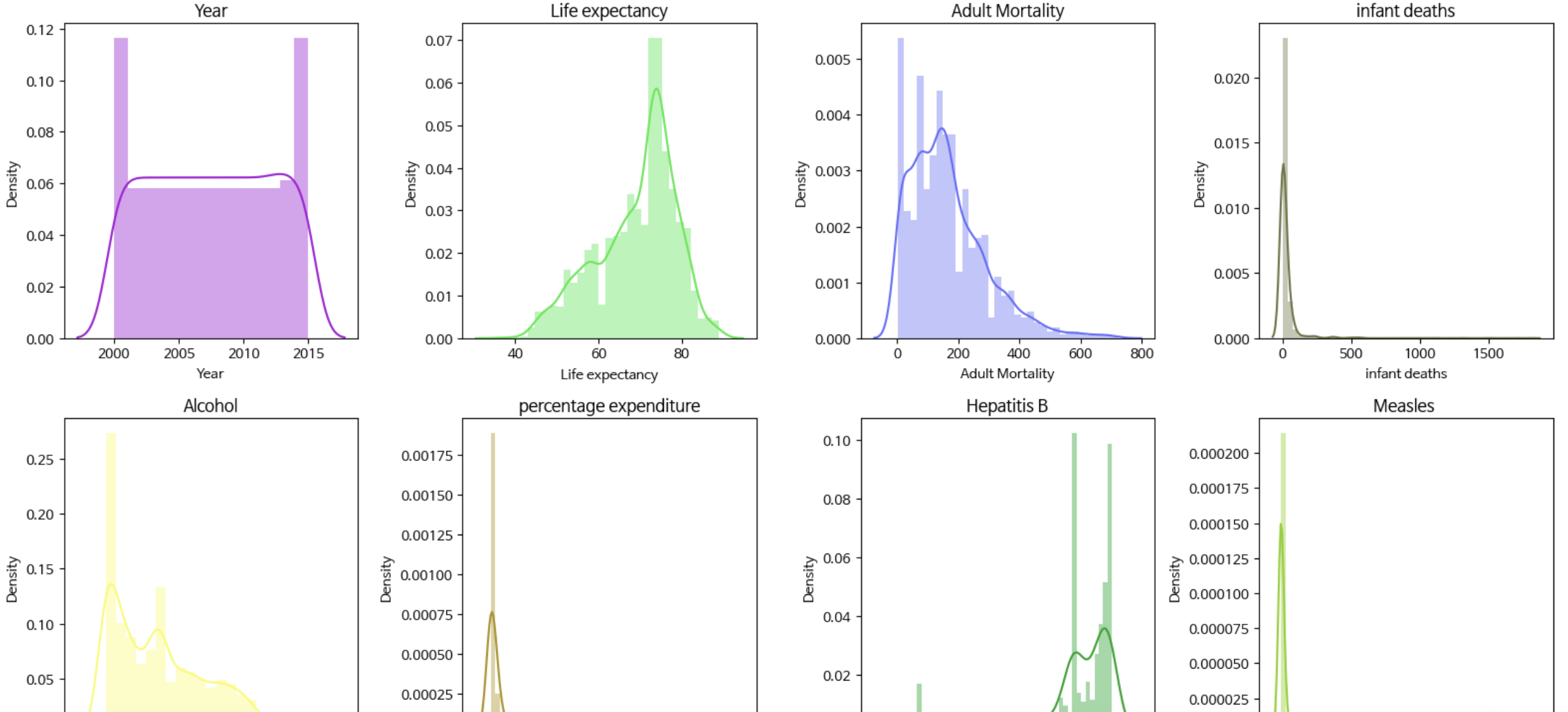
# 서브블롯으로 히스토그램 그리기
fig = plt.figure(figsize=(16,num_rows *4))
for k, col in zip(position, numerical_columns):
ax = fig.add_subplot(num_rows, 4, k)
sns.distplot(df[col], color=rand_color(), ax = ax)
ax.set_title(col)
#layout 조정
plt.tight_layout()
plt.show()rand_color() 메서드는 처음 본 것이다. 색상코드표가 # + 16진수여서 이것을 random.choice로 조합한 것이다.
df.select_dtypes(include=[np.umber]).columns.tolist() 라는 것이 생소해서 가져왔다.
판다스 사이트에서 가져온 것이다. numeric types만 가져오고싶을 때는 np.number나 number를 써야 된다고 한다.
따라서 df.select_dtypes(include=number).columns.tolist() 도 된다.
distplot이 생소해서 검색해봤는데 histplot()이나 displot()으로 대체된다고 한다. 근데 histplot()은 잘 나오는데 displot()은 뭔가 엉뚱하게 나온다.
import pandas as pd
Q1 = df['Life expectancy'].quantile(0.25)
Q3 = df['Life expectancy'].quantile(0.75)
IQR = Q3 - Q1
outliers = df[(df['Life expectancy'] < (Q1 - 1.5 * IQR)) | (df['Life expectancy'] > (Q3 + 1.5 * IQR))]
print('Q1:', Q1)
print('Q3:', Q3)
print('IQR:', IQR)
print('Outliers:')
print(outliers)
print(len(outliers))판다스의 quantile()메소드는 분위수를 구해주는 메서드이다. 1사분위수를 0.25 3사분위수를 0.75를 넣어 구한다.
IQR(inter-quartile range) : 사분위수 범위. 3사분위에서 1사분위를 빼주면 된다.
이상치는 사분위수 *1.5에 1사분위수를 뺀 값보다 작은 수치들 그리고 3사분위를 뺸 것보다 큰 수치들이 outlier다.
df.corr().round(2)['Life expectancy']
#round는 소숫점
correlation_matrix = df.corr()
plt.figure(figsize=(10, 10))
sns.heatmap(correlation_matrix, annot=True, fmt=".2f", square=False, cmap = 'coolwarm')
plt.show()히트맵 그리는 코드. annot=True하면 사각형에 숫자가 보임. fmt=".2f"하면 소숫점 2자리까지. sqaure=True하면 딱 정사각형으로 보임, cmap ='coolwarm'하면 파랑, 빨강 계통이 보임.
그리고 이상치 처리한 것을 쳐내다가 컬럼값이 달라져서 train_test_split을 할 때 오류가 있었다.
구분이 되었어도 인덱스 갯수는 다 맞아야 한다.
모르는 것 : 선형모델 생성 및 학습.
mean_squared_error, mean_absolute_error, r2_score,
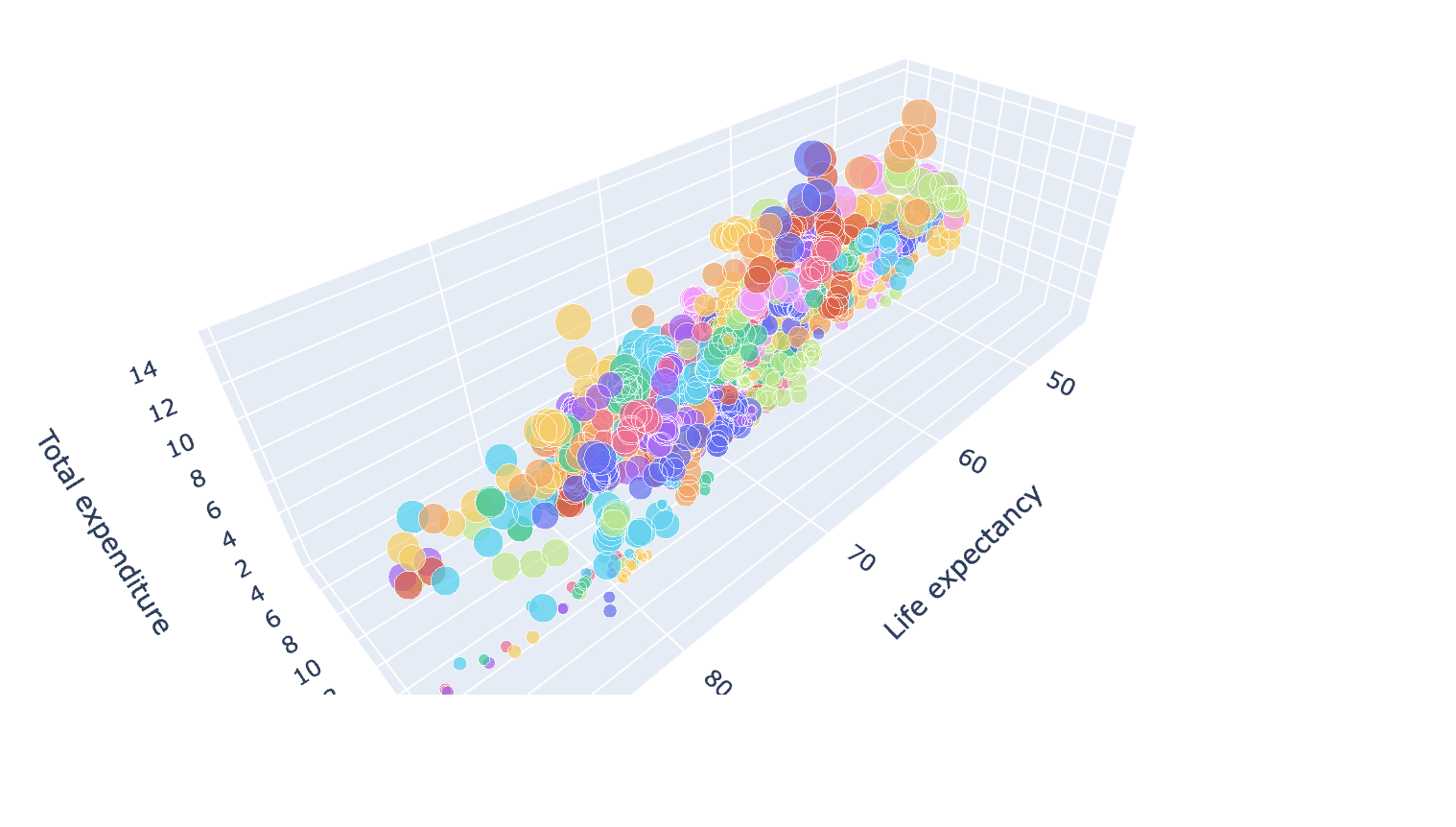
그리고 Plotly를 배웠다. 이거는 되게 직관적으로 볼 수 있고, 마우스에 호버링하면 무슨 데이터인지도 다 보이고, 3차원 스캐터도 만들어서 좋다.
'python' 카테고리의 다른 글
| 몽고디비와 파이썬이 SSL 문제로 연결이 안될 때. import certifi (0) | 2023.07.19 |
|---|---|
| 맥북 크롬 셀레니움이 갑자기 안된다. 115버전 ChromeDriver 해결법.(임시 불끄기) (0) | 2023.07.19 |
| 경기도미래기술학교 AI개발자 부트캠프 41일차 TIL- 베이즈 정리 복습의 복습. (0) | 2023.07.05 |
| 타이타닉 생존자 예측 프로젝트 해보기 1. 전처리 및 sns 뽑아보기. (0) | 2023.07.04 |
| 경기도미래기술학교 AI개발자 부트캠프 37일차 - 클러스터링(Clustering) 공부하기. (0) | 2023.06.30 |